
前言
最近因緣際會,複習了一些基礎的資料結構。在看到 Hash Table 的時候,也順便看了一下他的時間複雜度。不看還好,一看不得了,怎麼那麼小 (插入元素、移除元素跟找某個元素大概都只要 O(1) 的時間複雜度)!所以想要用很簡潔白話的方式說明一下 Hash Table 這個好用的資料結構。
簡介 Hash Table
Hash Table 是儲存 (key, value) 這種 mapping 關係的一種資料結構,從圖中可以很清楚地看到
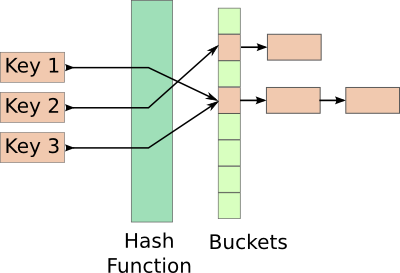
那為什麼他的時間複雜度這麼低呢? 舉例來說,如果我們有 n 個數字要儲存,一般大家常會用 array 來存。如果我們拿到另一個數字 A,要判斷這個數字 A 有沒有在 array 裡面,那我們勢必得跟 array 裡的元素一個個比較,時間複雜度是 O(n)。(先做過 sorting 的話,就可以用二分搜尋法比較快地找到,但還是需要 O(logn) 的時間複雜度)
但因為 hash function 的關係,如果先把 n 個數字儲存在 Hash Table 裡面,那如果要判斷這個數字 A 是不是已經被存在 Hash Table 裡面,只要先把這個數字丟進 hash function,就可以直接知道 A 對應到 Hash Table 中哪一格。所以其實是 hash function 幫我們省去了一個個比較的力氣。
如果想看 Hash Table 詳細的介紹跟實作,可以參考 @kdchang 之前寫過的用 JavaScript 學習資料結構和演算法:字典(Dictionary)和雜湊表(Hash Table)篇。
Hash Table 的秘密醬汁 - Hash Function
Hash Table 好不好用的關鍵跟這個神奇的 hash function 有很大的關係。讓我們想像一種情況,如果我們使用一個壞掉的 hash function,不管餵給這個 hash function 什麼內容他都會吐出同一個 index,那這樣的話就跟存一個 array 沒什麼兩樣。 搜尋的時間複雜度就會變成 O(n)。
以實用的角度出發,在簡單認識 Hash Table 的時候並不需要理解 hash function 要怎麼實作,但是我們要知道,hash function沒有完美的,有可能會把兩個不同的 key 指到同一個桶子,這就是所謂的 collision。當 collision 發生的時候,除了最直觀地增加 Hash Table 的桶子數,在每個桶子中用一個 linked list 來儲存 value、或是 linear probe 都是常用的方法,不過我們就先不細究下去。
Hash Table 有沒有什麼不好用的地方
最簡單的答案是,不該使用 Hash Table 的時候。例如想要處理一些有時間順序的 data,希望可以丟掉最先進來的資料優先,queue 顯然就是一個更好的選擇。
還有一個情況是,如果希望儲存的 data 可以被排序,那 Hash Table 就會不太好用。有個不錯的討論串在討論這個問題。
Hash Table 的應用
Hash Table 的一個簡單應用就是搜尋引擎(之前在 Udacity 上過一門課,裡面就會教大家怎麼用 Hash Table 的概念來做搜尋引擎的後台),例如在搜尋的時候輸入關鍵字,我們可以把這個關鍵字傳進 hash function,然後 hash function 就可以指出這個關鍵字對應到的桶子,這時候再到這個桶子裡搜尋網頁就可以了。
當然,如果你在某些時刻只能使用時間複雜度是 O(1) 的演算法來存取元素,那 Hash Table 絕對是你的好朋友。
用 Hash Table 來解一題簡單的演算法題目
我們先看個題目 - Two Sum,假設我們有一個 array,裡面儲存了一些數字,假設我有一個想要找到的數字 target,請找出 array 中兩個數字的 index,這兩個數字的和必須跟 target 一樣。
假設有 nums = [2, 7, 11, 15], target = 9,
因為 nums[0] + nums[1] = 2 + 7 = 9,
回傳 [0, 1]。
最直觀的作法是用兩層 for 迴圈,跑過所有可能的組合就可以了,但如果我們被要求只能用 O(n) 複雜度的演算法解出這題要怎麼辦呢。
一個方法就是用 Hash Table,做法是,當迴圈跑到nums[i]時,如果 target-nums[i]還不在 Hash Table中,那就儲存(nums[i], i),從題目的範例看一下:
nums = [2, 7, 11, 15]
target = 9
我們希望得到的答案是 0 跟 1 。 如果我在跑到 2 的時候就先儲存 (2, 0),這樣我在迴圈跑到 7 的時候,就會發現 9-7 已經在 Hash Table 裡,然後就可以取得 2 的 index(0)了。這樣演算法就會是 O(n) 的時間複雜度囉!
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
vector<int> ans;
map<int, int> indexMap;
map<int, int>::iterator iter;
for(int i=0; i<nums.size(); i++)
{
iter = indexMap.find(target-nums[i]);
if(iter != indexMap.end())
{
ans.push_back(iter->second);
ans.push_back(i);
return ans;
}
else
indexMap.insert(pair<int, int>(nums[i], i));
}
return ans;
}
};
(image via Vishesh Handa's blog)
感謝 KohakuBlueleaf 留言指正,正確的實作應該用 unordered_map:
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int, int> table;
for(int i = 0; i < nums.size(); i++) {
// If not in the table, insert the index
if( table.find( target - nums[i] ) == table.end() ) {
table[ nums[i] ] = i;
}
else {
return { table[ target-nums[i] ], i };
}
}
return {};
}
};
關於作者:
@pojenlai 演算法工程師,對機器人跟電腦視覺有少許研究,最近在鍛鍊自己的執行力


_@ar851060_https://static.coderbridge.com/images/covers/default-post-cover-2.jpg)


