Caffe & GoogLeNet,怎麼幫助機器人更好地辨識物體
簡介
這次要談的內容,是使用深度學習(Deep Learing)的模型來讓機器人做物體辨識。深度學習在這幾年來變得很火紅,相關的框架也相當多,這次之所以想談caffe,是因為已經有現成的方法可以將它應用到機器人上面。(有位台灣的開發者弄了一個叫做ros_caffe的package來串接ROS(機器人作業系統)跟Caffe,可以將Caffe辨識的結果丟到一個ROS的topic,其他的node就可以自己取用。這使得機器人辨識物體的能力得以大幅增加)
一點點幫助入門的細節
基本的安裝方法可以參考這個連結,假設已經裝成功,那至少就已經有基本的環境可以用(有一個caffe的資料夾被放在你安裝的路徑),接下來需要下載GoogLeNet的model,只要用caffe/scripts資料夾裡的程式幫忙就行了:
$./scripts/download_model_binary.py ./models/bvlc_googlenet
上面這個指令會將GoogLeNet的model下載到caffe/models/bvlc_googlenet,假設已經下載好model,接下來就可以用一個小程式來跑跑看GoogLeNet了:
1 | import numpy as np |
接下來只要執行(因為程式放在examples資料夾底下):
$python ./examples/googlenet_example.py
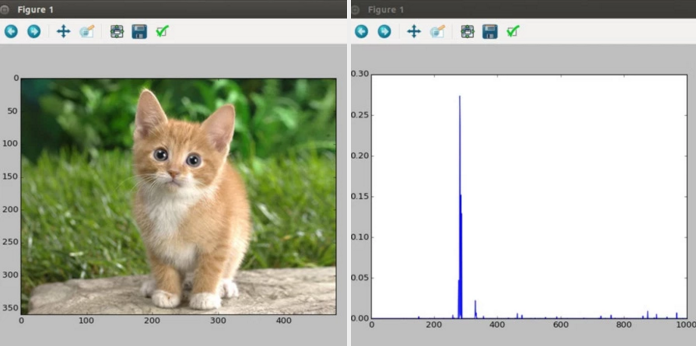
就可以看到一隻貓的影像,關掉影像之後就會看到貓的類別:
串接ros_caffe
如果想往下跟ros_caffe的串接可以參考外國鄉民的文章,裡面有完整而詳細的步驟。如果你已經安裝過caffe,可以參考這個issue。
需要注意的是,外國鄉民跑的只有global的結果,也就是一張影像中只有一個最顯著的物體會被辨識,如果要辨識一張影像中的各個物體,可能就要自己在中間串接一個負責做segmentation的node,再把各個切出來的區塊餵給ros_caffe來做辨識。
關於作者:
@pojenlai 演算法工程師,對機器人跟電腦視覺有少許研究,最近在鍛鍊自己的執行力
留言討論