使用 Object Recognition Kitchen 的 Linemod 演算法辨識物體
前言
這次要介紹的工具是 ROS 裡面專門用來作物體辨識的 Object Recognition Kitchen (以下簡稱為 ORK ),這個工具比較像是一個框架,裡面包含了好幾種演算法(你可以根據自己的需求使用不同的演算法),這篇文章要介紹的只是其中一種 – Linemod 。 Linemod 是一個辨識效果很不錯的 3D 物體辨識演算法(不過一個使用條件是物體須是剛體),所以想藉此機會分享給大家,以後只要你想要,就可以直接拿這個工具來串自己的機器人應用。
安裝 ORK & Linemod
雖然 ORK 的開發者已經寫了一份滿不錯的安裝 tutorial,不過我覺得還是值得為他再寫一份自己的整理筆記,可以把過程中遇到的一些問題都整理下來供大家參考。
我目前跑起來的環境是 Ubuntu 14.04+ROS Indigo,首先來裝一些 ORK 需要用到的 package !
1 | export DISTRO=indigo |
接下來就要安裝 ORK 啦,然後因為我比較喜歡 build from source,所以我會下面會放上一份複雜版的安裝方法,裡面會有比較多跟 error 奮鬥的過程,如果你比較喜歡直接玩應用,安裝什麼的懶得管,那看簡單版的安裝方式其實就可以了。
超簡單版安裝方式
超簡單版顧名思義就是超簡單,完全不要管我們會用到哪些 package,只要是 ORK 底下的 package,都裝下去,缺點就是會多浪費一些硬碟空間。只要用一行指令就搞定:
1 | sudo apt-get install ros-indigo-object-recognition-kitchen-* |
稍微理解自己裝了什麼的安裝方式
1 | sudo apt-get install ros-indigo-object-recognition-core ros-indigo-object-recognition-linemod ros-indigo-object-recognition-msgs ros-indigo-object-recognition-renderer ros-indigo-object-recognition-ros ros-indigo-object-recognition-ros-visualization |
Build From Source版安裝方式
首先來先裝跟 ROS 銜接的 package,首先要先開啟 terminal,切到 catkin_workspace/src 底下
1 | git clone http://github.com/wg-perception/object_recognition_msgs |
然後因為今天的主角是 linemod,所以需要安裝相關 package
1 | git clone http://github.com/wg-perception/object_recognition_core |
在 catkin_make 的過程中可能會碰到因 error 而中斷,會看到類似如下的訊息:

這時候不要怕,繼續給他 catkin_make 下去,你就會發現編譯進度會神奇地有進展:
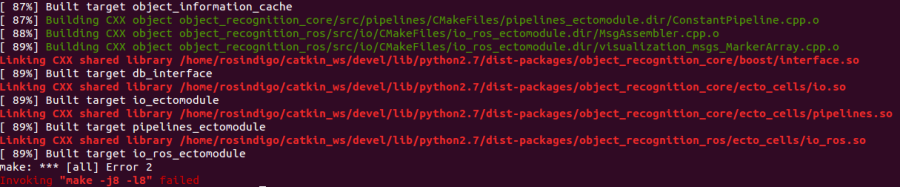
不過我有碰到一個問題,再怎麼重新編譯都沒有用:
1 | In file included from /home/rosindigo/catkin_ws/src/ork_renderer/src/renderer3d.cpp:50:0: |
因為是少了 GL/osmesa.h,所以需要額外下一個指令 sudo apt-get install libosmesa6-dev 來安裝。
裝到這邊還會有一個問題,就是雖然編譯都已經過了,但 roscd object_recognition_core 時都會出現無法找到此 package 的 error,由於這會對後續要執行演算法時造成問題,所以還是要來處理一下。
我們先重新理一下思路,理論上,編譯過之後就會被加入到 roscd 可以找到的 path 中,但是 roscd 顯然就表示沒有被加進 ROS_PACKAGE_PATH 中,google 了一下發現到有人也遇過類似的問題,解法也確實就是把我們 git clone 下來的那些 package 加入到 ROS_PACKAGE_PATH 中,這樣的話問題就簡單啦!
先 vim ~/.bashrc 一下,然後在最下面補上一行:
1 | export ROS_PACKAGE_PATH="$ROS_PACKAGE_PATH:/home/rosindigo/catkin_ws/src" |
補完的結果看起來就像:

接上並從 RGB-D Sensor 收資料
接下來我們要先處理感測器這塊,畢竟如果沒有感測器,那就根本不用辨識物體的對吧。原本官方教學上是建議用 roslaunch openni2_launch openni2.launch,但因為我是用 Kinect 1,要用 roslaunch openni_launch openni.launch。
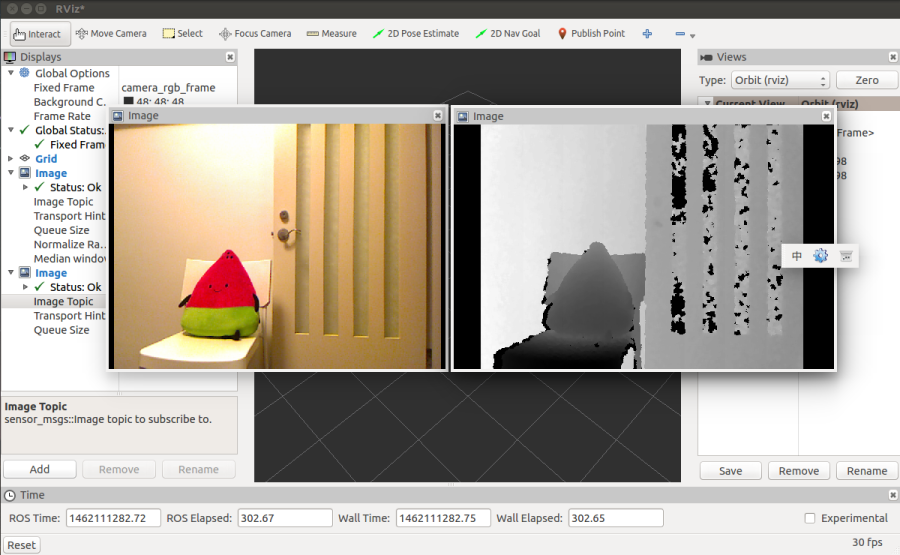
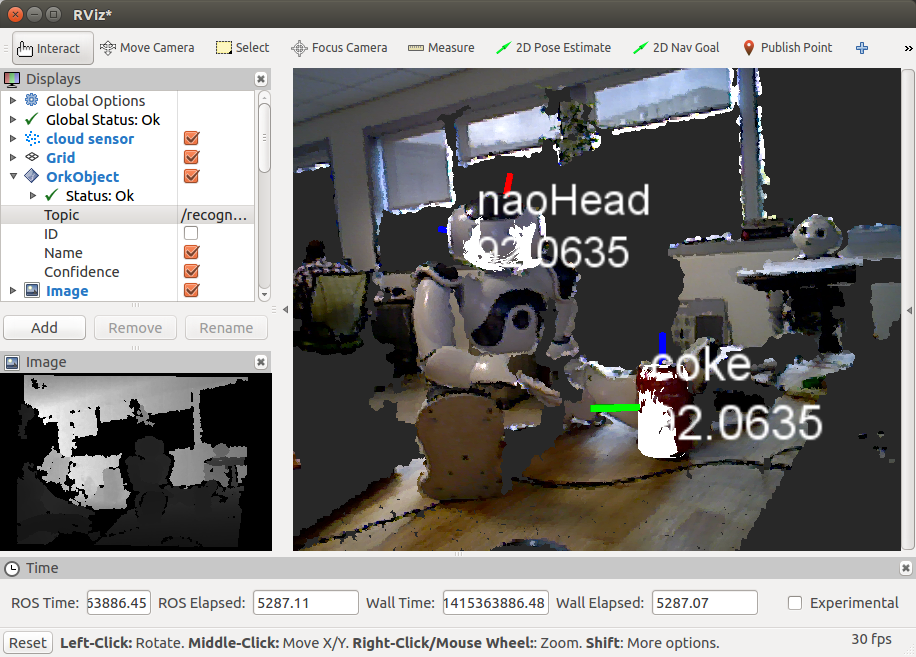
跑起來之後應該就可以在 Rviz 看到以下的畫面:
安裝物體辨識資料庫 & 加入 model
ORK 是一套以 template matching 方法為主的辨識工具,也就是說,他會把感測器看到的物體跟資料庫中的物體比對,夠相似的就算是辨識成功,所以我們接著要來處理資料庫這一塊。首先要安裝 CouchDB 這個工具 (用 sudo apt-get install couchdb )。
接下來檢查一下是否有安裝成功 (用 curl -X GET http://localhost:5984 )。如果成功,應該會看到類似下面的畫面:

1 | rosrun object_recognition_core object_add.py -n "coke " -d "A universal can of coke" --commit |
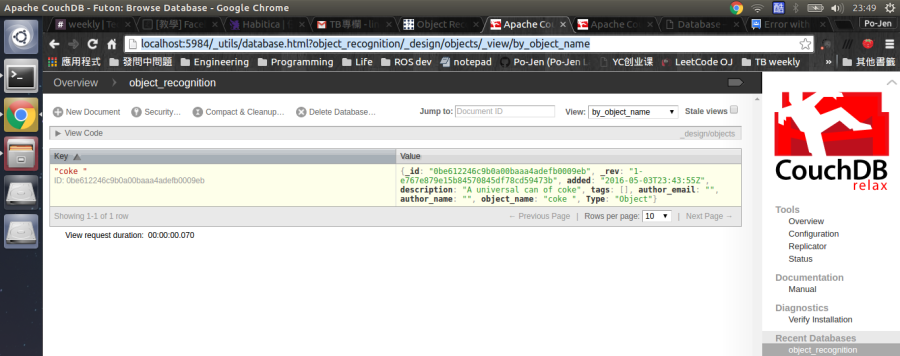
執行上面這個指令之後,你可以去 http://localhost:5984/_utils/database.html?object_recognition/_design/objects/_view/by_object_name 看看自己的資料庫裡是否已經新增了這個物體:
接下來就是要指定這個物體的 3D 模型是什麼,這邊就需要先下載個 package 並編譯。
1 | git clone https://github.com/wg-perception/ork_tutorials |
ork_tutorials裡面有一個 coke.stl 檔,他就是一個可樂罐的 3D 模型,足夠讓我們先用來辨識。注意下面這個指令中有一串看起來像亂碼的東西,但那其實是物體的 id ,這就要從你自己的資料庫裡去看了。
1 | rosrun object_recognition_core mesh_add.py 0be612246c9b0a00baaa4adefb0009eb /home/rosindigo/catkin_ws/src/ork_tutorials/data/coke.stl --commit |
執行 Linemod 演算法 (Training & Detection)
好了!終於要進入正題了,這一塊一樣有 官方tutorial 可以參考,我們先從 Training 開始。
1 | rosrun object_recognition_core training -c `rospack find object_recognition_linemod`/conf/training.ork |
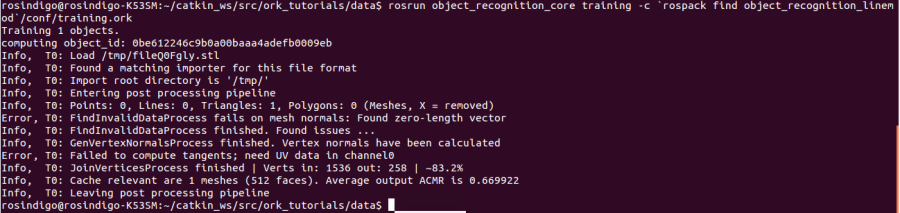
這個 training 指令會利用資料庫裡的 3D 模型建立辨識時所需要的 template,如果執行成功,你會看到如下的訊息:
如果已經訓練完畢,下一步就是用他來辨識物體啦。
可惜筆者的 Kinect 突然壞掉了,沒有辦法直接 demo 出來,不過這邊的指令也不會很複雜。
1 | roslaunch openni_launch openni.launch |
接下來就可以用 Rviz 來看辨識結果啦!
演算法簡介
既然 Linemod 是一個這麼強大的演算法,試著去稍微了解一下演算法也是很合理的,原始的論文在這邊 (2011 ICCV 的 oral 論文),以下的圖片也是出自這篇論文。
首先來看一下這篇論文的辨識結果:

這個演算法的核心概念就是整合多種不同的 modalities,把 modality 想成物體的不同特徵可能比較好懂,例如下圖中就有兩種 modalities – gradient 跟 surface normal,而因為這兩種特徵所表達的特性不一樣,所以可以互補,進而達到更好的辨識效果。
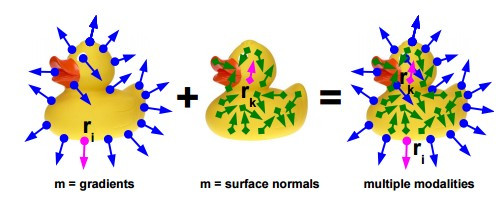
所以說,Linemod 需要先有已知的物體模型,然後先取得這個物體各種 modlaities 的template,這樣在辨識的時候就可以拿 template 來比對。
不過這概念在電腦視覺領域中並不特別,因為同時使用不同特徵來加強物體辨識的效果是很直覺的,也有很多不同的方法可以做到這件事情,所以這篇論文還提出了一個方法來增進 similarity measurement 的效率 ( similarity measurement 的意思是 measure 儲存的 template 跟現在看到的影像資料有多接近)。
總結
這篇文章很簡略地介紹了 ORK 的安裝、基本的使用方式(使用 Linemod )、還有演算法簡介,有興趣的讀者可以自己動手玩玩看 (如果沒有實體的 RGB-D sensor,你也可以試著用 Gazebo 裡面的 Kinect 來模擬)!
延伸閱讀
關於作者:
@pojenlai 演算法工程師,對機器人跟電腦視覺有少許研究,最近在鍛鍊自己的執行力
留言討論