來寫個氣象機器人吧!(Part 2)
Let’s build a weather bot!
此篇承接上一篇 來寫個氣象機器人吧!(Part 1)。
可以先玩看看氣象機器人,第一次使用請先輸入 help 來查看指令:
機器人回應設計思路
在繼續閱讀之前,希望大家能先看這篇「聊天機器人的開發思路」,這篇文章介紹了機器人回應的幾種模式,以及適用情況。那麼接著就是要考慮我在氣象機器人中,要採用下列模型的哪一種了:
- 樣板式模型 (Rule-based model)
- 檢索式模型 (Retrieval-based model)
- 生成式模型 (Generative model)
這個時候就要思考一下,使用者會如何對氣象機器人說話,以及氣象機器人會回應什麼資訊?
簡單舉例的話,大多數使用情形可能就是:「明天會下雨嗎?」、「今天天氣好嗎」、「明天氣象預報」、「台北天氣如何」、「台大現在空氣品質怎樣?」「需要帶傘嗎?」「要戴口罩嗎?」
上面我列出一個人想問天氣的時候最可能的問句,事實上如果你想查天氣,大概會對 Google 下搜尋的句子就是這樣。

簡單分析一下上面這些問句,每個句子都有關鍵字,例如:
- 天氣關鍵字:「天氣」、「預報」、「空氣品質」
- 天氣抽象名詞:「傘」、「口罩」
- 時間關鍵字:「今天」、「明天」
- 地點關鍵字:「台北」、「台大」
你會發現,當你想要知道氣象資訊時,一個句子的組合大概就是:
[地點][時間][天氣關鍵字|天氣抽象名詞]
在這個情況下,氣象機器人其實只需要用樣板模型就可以達成需求了,並且精準度也可以達到幾乎百分之百。因為在查詢天氣的時候,我們不需要判斷使用者的隱晦含義,或是句子是正向還是負向含義,因此不需要語意分析、機器學習等等方法介入。
此外即使是多輪對話的形式,還是可以只靠樣版模型就可以了,我們剛剛提到三要素,地點、時間、天氣關鍵字,所以最多只需要三輪對話,例如使用者只說了「台北」,機器人就問他說要哪個「時間」,再問他說要知道「空氣品質」還是「天氣狀況」。
但事實上,氣象機器人大多情況只需要一輪就夠了。因為假設使用者只說「地點」,那我們可以預期他就是問現在狀況,頂多一週天氣趨勢。當使用者只說「時間」或「天氣關鍵字」,我們可以預期地點是他發訊息的所在地。
因此其實氣象機器人不需要多輪式對話,因為查詢天氣就是一個很單純的動作,即便使用者輸入並未得到想要的資料,只要重新下夠明確的句子,例如「下週二紐約氣象預報」就可以得到答案。
樣板式模型實作
樣版式模型其實感覺也什麼技巧,但要注意樣板能應付所有情況。此外樣板模型其實就是決策樹,採用時要注意路徑的設計,例如以天氣查詢來說,路經應該是「天氣關鍵字」優先判斷,才會進入「地點」或「時間」的判斷。當句子只有地點或時間時,假設是一對一情況下,使用者只說「台北」,你大概能猜他想問台北天氣。但因爲機器人能在群組中使用,這時候有明確的「天氣關鍵字」出現,才能準確做出回應。
例如以「天氣」指令來說,我的邏輯是這樣:
1 | // ... |
所以假設今天句子是「台北天氣」,就會是找台北現在天氣。如果句子是「明天台北天氣」,就會去找氣象預報的資料。你可能會好奇那「地點」呢?其實我是在 getForecast() 和 getWeather() 函數底下才處理地點。
決策樹的細節我就不多作介紹,大致上就是用這樣的判斷方式把所有使用者可能會下的問句都解析並回應。
資料來源
一個氣象機器人最重要的部分就是氣象資料了,一般來說資料取得有幾種方式:
- 爬蟲
- 公開 API
- 隱藏版 API
爬蟲
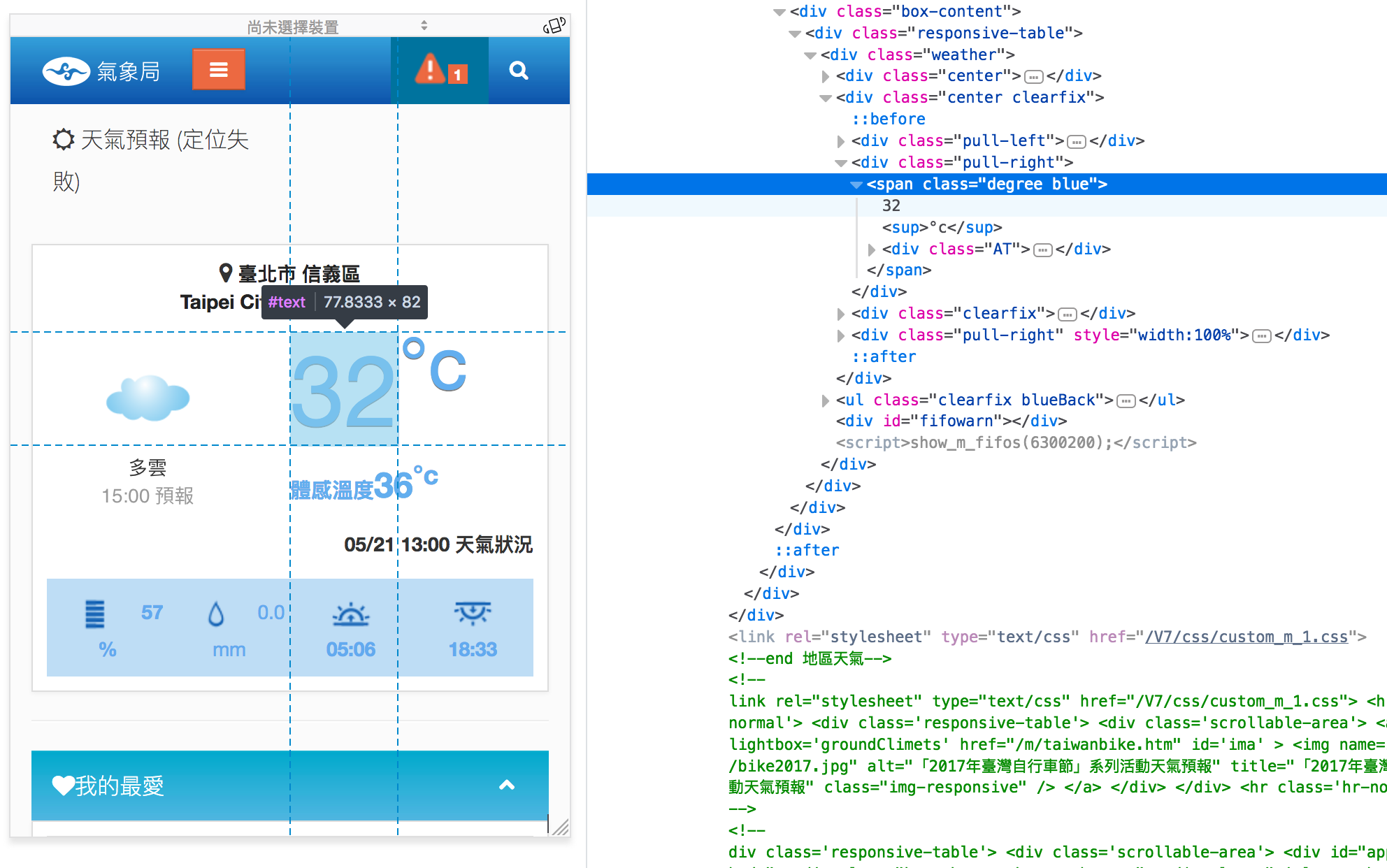
所謂爬蟲就是去開網頁,找出網頁原始碼中的資料,並擷取出來,例如我可以去找氣象局網站中的氣溫數字,在原始碼中就會長這樣:
公開 API
公開 API 就是一些開放平台,或是商業機構,提供正式的 API 服務,可以藉由這些 API 取得你要的資料。例如:
- 氣象資料開放平臺:氣象局的公開資料
- Open Weather Map:國外的氣象資料服務商
還有很多,就不多列舉了。
隱藏版 API
這個技巧通常初學者都不知道,特別介紹一下。剛剛提到說,爬蟲是去抓 HTML 的欄位資料,但是很多時候 HTML 是透過 JS 事後補上去的。是的,這就是 MVC 框架下的網站架構。網站會先渲染版面,然後再由 HTTP Request 呼叫他自己的 API 取得剩下的資料,並用 JS 把資料補到渲染畫面上。
所以我們要做的事情就是,攔截網站自己的 API,這些 API 不是公開的,但是我們也可以拿來用。不過風險是,因為這些 API 不是對外公開的,可能用法或是名稱常常再改變。
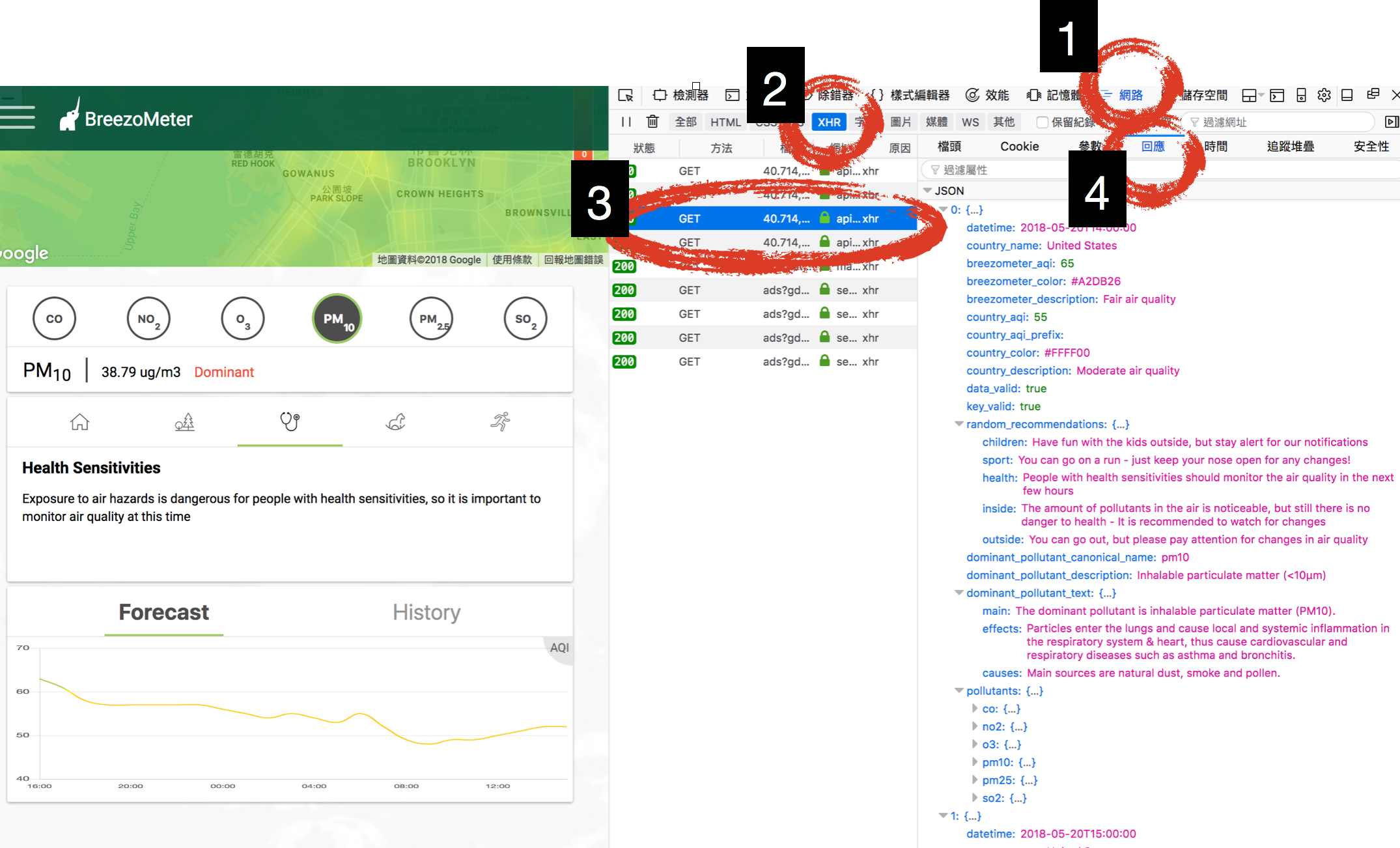
以上圖為例,Breezo Meter 是一個可以查空氣品質的網站,我想看看它是不是有自己的 API,所以我打該網頁,然後開啟「開發者工具」,點開「網路」然後選「XHR」。
這時候我們會看到有好幾筆資料,我就每一筆都點開看看,然後看「回應」的部分,所謂回應就是 HTTP Request 的 Response,如果他是一隻 API,就會看到 Json 格式的資料,然後我們就成功攔截 API 了!我們就可以直接使用隱藏版 API 來取得資料,通常會比寫爬蟲還方便,但風險就是他可能隨時會變。
資料處理
資料庫
我有兩台伺服器分別處理不同聊天平台,但資料庫應該要共用,所以把資料部分獨立出來。資料庫部分我使用 Firebase,因為 Firebase 不需要去管伺服器的問題,比起我自己在弄一台專門的資料庫伺服器方便。
資料庫主要是用來記錄一些高成本的資訊,例如「空氣品質的圖」其實是兩張圖片合成,每次有使用者查詢都合成一次很浪費資源,所以在第一位使用者查詢時,跑過一次影像處理就把他存起來,在同時間內有其他查詢就直接調用資料庫。
這邊可能會有問題,為什麼不用伺服器定時跑資料存到資料庫?這是因為目前使用者大約一千,查詢頻率其實沒有到很高,所以想說愛地球,有需要再跑就好。
一般做法都是把所有可能會調用的資料都用固定排成先跑好,像是爬蟲、調用 API、圖片處理等等都每隔一段時間自動執行並儲存,只是我覺得使用量還沒那麼大所以沒這樣做。
圖片
氣象機器人可以直接下關鍵字得到天氣圖、衛星圖、預報圖等,甚至我連地震圖都支援。但是 Line 規定圖片來源要是 HTTPS,很遺憾中央氣象局只有 HTTP,所以我必須先把圖片傳給第三方圖片服務商,這邊我是用 Imgur。然後再把上傳 Imgur 的圖片傳到 Line 上。因為圖片轉介很花時間,而且同一張圖片其實可以再利用,所以最後傳到 Imgur 的圖片都會用 Firebase 記錄起來。
氣象資料
原始氣象資料可能會需要處理,例如:
- 體感溫度必須自己從測站資料去算
- 風向都是數字,要轉成方位
- 空氣品質好壞指標 AQI 是數值,要轉換成描述文字例如「對過敏族群不健康」
簡單明瞭地把數據呈現給使用者也很重要。
關鍵字的處理
時間
要能辨識句子的時間,才能知道要給哪個時間的資料,所以機器人要能辨識「明天晚上」、「今天 20:00」、「明天 6:30pm」這類的時間語句。
這邊我採用 Chrono Node,他辨識的能力真的滿不錯的,而且支援英文中文混雜。不過我後來發現他中文支援度不完整,例如中文的「前天」、「後天」、「大後天」並不支援,所以我有幫忙寫補丁,不過發 Pull Request 之後作者一直沒有回應,感覺是沒在維護了。所以氣象機器人是安裝我自己修改過的 fork 版本。
Chrono 處理中文時間方法我覺得滿不錯的,這邊簡單示例:
由於中文表示時間的組合就那麼多,所以全部列出來。
1 | var PATTERN = new RegExp( |
根據中文描述轉換成時間概念。
1 | // ..... |
上面只是中文處理的部份而已,可以把「明天晚上」、「後天早上」等時間概念轉換成 Date() 物件。此外 Chrono 最好用的部分是不同語言的模組互通,所以可以混搭例如「明天 8:00pm」。中文數字處理以及英文時間判斷就留給讀者自行去看原始碼囉!
此外在開發過程中我被「時間」折騰個半死,因為伺服器在美國,使用者應該是在台灣(很不嚴謹的假設,我還沒去研究如何從 line 或 messenger 中取得使用者時區),中央氣象局資料時間是台灣時間,所以要一直轉換來比對時間。
轉換時間真的是暈頭轉向:
- 伺服器收到訊息,要判斷句子中的時間,然後假設使用者是在台灣,以此換成 UTC 標準時間。
- 再將伺服器時間也轉成 UTC 標準時間,比較句子時間與伺服器時間,檢查時間是否在未來。
- 是未來就去撈氣象局預報資料,並將氣象局資料轉成 UTC 標準時間,找出與句子時間符合的氣象數據。
此外 NodeJS 的國際化元件(ICU)原來預設是裝 small-icu,想要完整的話要裝 full-icu。國際化元件可以讓時間表達成中文,原本 NodeJS 會直接將晚上八點表達成 20:00,但是完整的國際化元件可以讓他表示成 下午 8:00。
1 | npm install full-icu --save |
執行 NodeJS 的時候要這樣來使用完整的國際化元件:
1 | node --icu-data-dir=./node_modules/full-icu index.js |
地點
要判斷句子中的地點真的很難,世界的地名五花八門,連「太陽」都可以是地名。我的處理辦法是分台灣地區和國外地區。
- 台灣地區:台灣的行政區最低層級是村或里,全部加起來也才不到一萬個,所以台灣地區先建檔,可以很明確的辨識出來。檔案包含縣市、鄉鎮市、村里和經緯度資訊。
- 非行政地區、國外地區:如果是非行政區的地名,例如台灣大學、總統府等等,或是國外的地區,例如紐約、東京等。這時候我會用 Google Map Api 來查對應的經緯度。
為什麼都是經緯度呢?
- 台灣地區會去查使用者查詢地點的最近的測站,因為我有每個測站的經緯度,所以會去算彼此距離,並取得數據。例如查台北公館天氣狀況,因為台灣大學就有觀測站(台大就在公館),所以會得到台灣大學觀測站的數據資料。
- 國外的氣象 API 通常都是用經緯度當參數。
值得一提的是,台灣的氣象測站真的很密,台灣的氣象測站大約有四百個,但是如果換在國外的話,一個台灣大小的區域,可能只有一個測站。所以國外服務商的氣象資訊常常都是使用內插外插來取得近似值,換言之就是很不精確啦!但台灣因為太密了,直接找最近的測站的數據就好,而且很準!
地名處理
由於中文字整串黏在一起的特性,要能準確判斷他是不是地名,不能直接用這樣判斷:
1 | if(message.includes("北海道")) |
因為原句可能是「北海、道路」,大概是這種感覺。
這邊我用結巴分詞,來把句子切割成一個個詞。這個模組簡單原理就是用詞頻來決定要不要做切割。不過其實在預設問句中一定要有地名的情況下,這樣做用處不大。實際比較有感可能是像 Siri 這種可以回答各種天馬行空問題的機器人才要能正確辨識是不是有地名的概念,還是只是湊巧兩個字連在一起罷了。但考量未來可擴充性,我先採用比較高級一點的方式處理。
總結
我大致上已經將我如何實作氣象機器人的技術都介紹了,未來我會持續讓他越來越好,目前樣板式模型最大缺點就是會有無法辨識的情況,這時候我會回應讓使用者直接查看使用說明,但真正好的服務是不需要使用說明的,一個好的聊天機器人應該跟人一樣聰明對吧?
很高興不知不覺就有超過一千名使用者,隨者使用者變多,未來架構可能也還會需要調整,如同所有規模逐漸成長的公司的後端架構一樣,A/B 測試、紅藍部署等等技術都是隨著規模擴大而將慢慢導入。
你可以在這邊查看氣象機器人的 Github Repo
關於作者
劉安齊
軟體工程師,熱愛寫程式,更喜歡推廣程式讓更多人學會。歡迎追蹤 **微中子**,我會在上面分享各種新知與最新作品,也可以去逛逛我的 個人網站 或 **Github**。
留言討論